Reproducing the Clark and Golder (2006) Example from Rainey (2014)
hypothesis tests
confidence intervals
equivalence tests
TOSTs
negligible effects
computing
R
marginaleffects
In this post, I try out the {marginaleffects} package to conduct two one-sided tests (TOSTs) to test a hypothesis of a negligible effect (i.e., equivalence testing).
Author
Carlisle Rainey
Published
August 18, 2023
Background on arguing for a negligible effect
I remember sitting in a talk while I was a graduate student, and the speaker said something like: “I expect no effect here, and, just as I expected, the difference is not statistically significant.” Of course, that’s not a compelling argument for a null effect. A lack of statistical significance is an absence of evidence for an effect; it is not evidence of an absence of an effect.
But I saw this approach taken again and again in published work. (And still do!)
My first publication was an AJPS article (Rainey 2014) (Ungated PDF) explaining why this doesn’t work well and how to do it better.
Here’s what I wrote in that paper:
Hypothesis testing is a powerful empirical argument not because it shows that the data are consistent with the research hypothesis, but because it shows that the data are inconsistent with other hypotheses (i.e., the null hypothesis). However, researchers sometimes reverse this logic when arguing for a negligible effect, showing only that the data are consistent with “no effect” and failing to show that the data are inconsistent with meaningful effects. When researchers argue that a variable has “no effect” because its confidence interval contains zero, they take no steps to rule out large, meaningful effects, making the empirical claim considerably less persuasive . (Altman and Bland 1995; Gill 1999; Nickerson 2000)
But here’s a critical point, it’s impossible to reject every hypothesis except exactly no effect. Instead, the researcher must define a range of substantively “negligible” effects. The researcher can reject the null hypothesis that the effect falls outside this range of negligible effects. However, this requires a substantive judgement about those effects that are negligible and those that are not.
Here’s what I wrote:
Researchers who wish to argue for a negligible effect must precisely define the set of effects that are deemed “negligible” as well as the set of effects that are “meaningful.” This requires defining the smallest substantively meaningful effect, which I denote as \(m\). The definition must be debated by substantive scholars for any given context because the appropriate \(m\) varies widely across applications.
Clark and Golder (2006)
Clark and Golder (2006) offer a nice example of this sort of hypothesis. I’ll refer you there and to Rainey (2014) for a complete discussion of their idea, but I’ll motivate it briefly here.
Explaining why a country might have only a few (i.e., two) parties, Clark and Golder write:
First, it could be the case that the demand for parties is low because there are few social cleavages. In this situation, there would be few parties whether the electoral institutions were permissive or not. Second, it could be the case that the electoral system is not permissive. In this situation, there would be a small number of parties even if the demand for political parties were high. Only a polity characterized by both a high degree of social heterogeneity and a highly permissive electoral system is expected to produce a large number of parties. (p. 683)
Thus, they expect that electoral institutions won’t matter in socially homogeneous systems. And they expect that social heterogeneity won’t matter in electoral systems that are not permissive.
Reproducing Clark and Golder (2006)
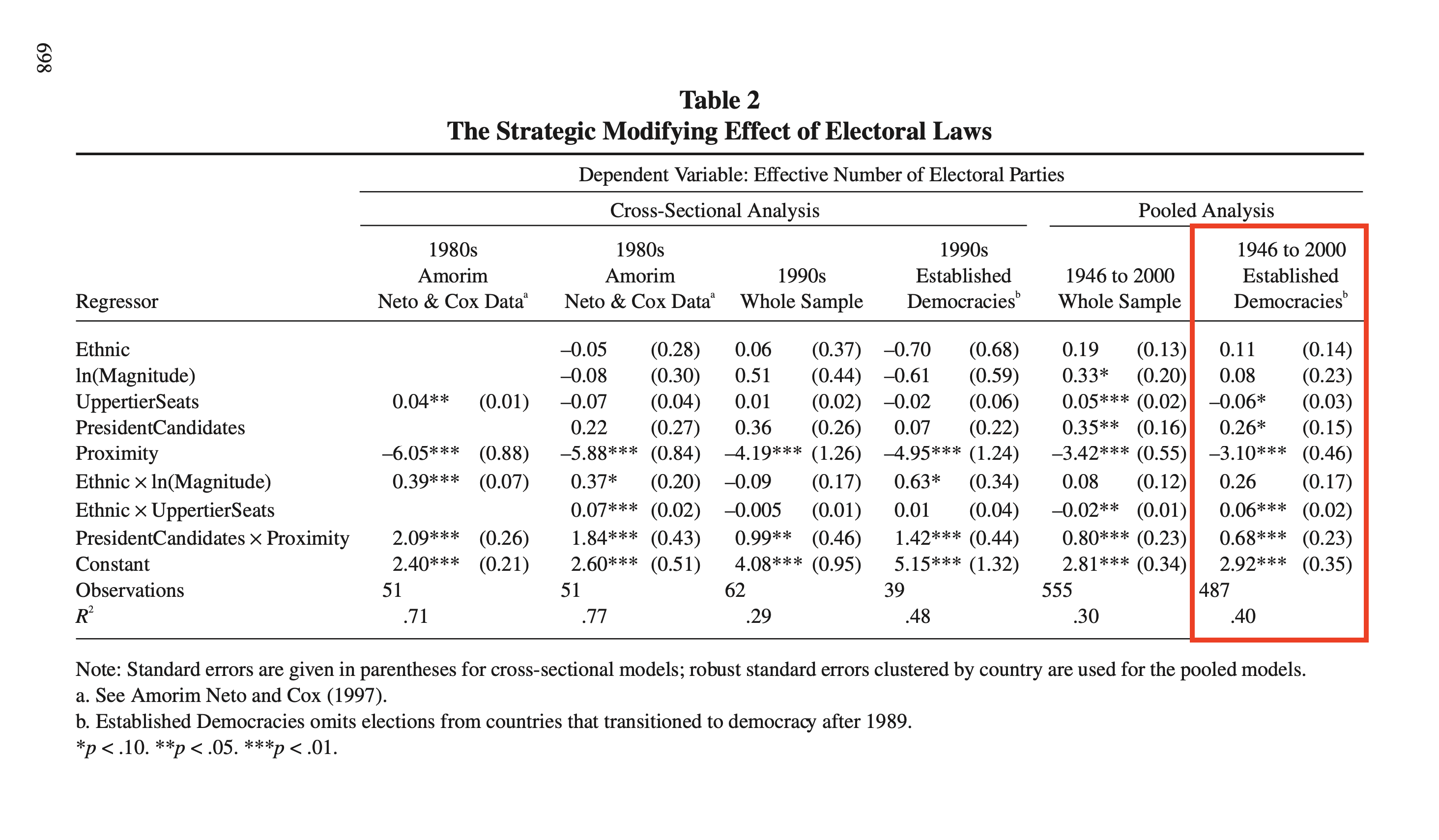
Before computing their specific quantities of interest, let’s reproduce their regression model. Here’s their table that we’re trying to reproduce.
And here’s a reproduction of their estimates using the cg2006 data from the {crdata} package on GitHub.1
1 Run ?crdata::cg2006 for detailed documentation of this data set.
# load packageslibrary(tidyverse)library(sandwich)library(modelsummary)# install my data packages from githubdevtools::install_github("carlislerainey/crdata") # only updates if newer version available# load clark and golder's data setcg <- crdata::cg2006# reproduce their estimatesf <- enep ~ eneg*log(average_magnitude) + eneg*upper_tier + en_pres*proximityfit <-lm(f, data = cg)# regression tablemodelsummary(fit, vcov =~ country, # cluster-robust SE; multiple observations per countryfmt =2, shape = term ~ model + statistic)
(1)
Est.
S.E.
(Intercept)
2.92
0.35
eneg
0.11
0.14
log(average_magnitude)
0.08
0.23
upper_tier
-0.06
0.03
en_pres
0.26
0.15
proximity
-3.10
0.46
eneg × log(average_magnitude)
0.26
0.17
eneg × upper_tier
0.06
0.02
en_pres × proximity
0.68
0.23
Num.Obs.
487
R2
0.397
R2 Adj.
0.387
AIC
1672.5
BIC
1714.3
Log.Lik.
-826.229
RMSE
1.32
Std.Errors
by: country
Success!
They use averge_magnitude to measure the permissiveness of the electoral system and eneg to measure social heterogeneity.
Using comparisons() to compute the effects
Now let’s compute the two quantities of interest. Clark and Golder argue for two negligible effects, which I make really concrete below.
Hypothesis 1 Increasing the effective number of ethnic groups from the 10th percentile (1.06) to the 90th percentile (2.48) will not lead to a substantively meaningful change in the effective number of political parties when the district magnitude is one.
Hypothesis 2 Increasing the district magnitude from one to seven will not lead to a substantively meaningful change in the effective number of political parties when the effective number of ethnic groups is one.
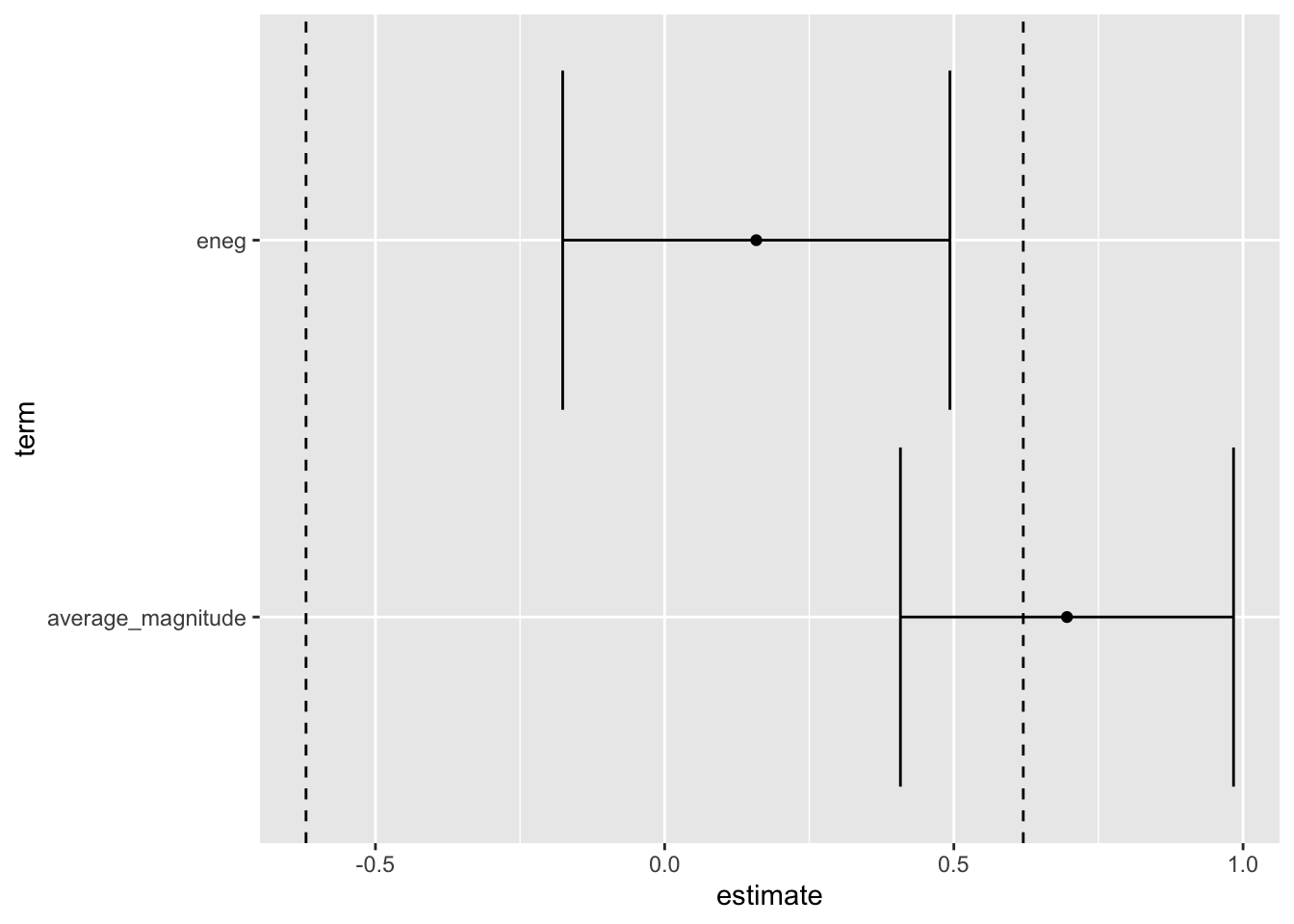
And comparing the U.S. and the U.K., I argue that the smallest substantively interesting effect is 0.62. In Rainey (2014), I made the plot below. I want to reproduce it with {marginaleffects}.
These differences (and the 90% CIs) are really easy to compute using {marginaleffects}!2
2 I’m only doing Clark and Golder’s original results, not any of the robustness checks.
# load packageslibrary(marginaleffects)# the smallest substantively interesting effectm <-0.62# a data frame setting the values of the "other" variablesX_c <-data.frame(eneg =1.06, # low valueaverage_magnitude =1, # low valueupper_tier =0,en_pres =0, proximity =0)# compute the comparison for eneg and average magnitudec <-comparisons(fit,vcov =~ country,newdata = X_c, variables =list("eneg"=c(1.06, 2.48), # low to high value"average_magnitude"=c(1, 7)), # low to high valueconf_level =0.90)
This c outputted from comparisons() is a data frame.
Now we can just plot the 90% CIs with ggplot() and check whether the entire interval falls inside the bounds.
# bind the comparisons together and plotggplot(c, aes(x = estimate,xmin = conf.low,xmax = conf.high, y = term)) +geom_vline(xintercept =c(-m, m), linetype ="dashed") +geom_errorbarh() +geom_point()
In this case, we conclude that social heterogeneity (eneg) has a negligible effect because the 90% CI only contains substantively negligible values. However, the 90% CI for district magnitude (average_magnitude) contains substantively negligible and meaningful values, so we cannot reject the null hypothesis of a meaningful effect.
Computing the TOST p-values using hypotheses()
It’s then almost trivial to use the hypotheses() function to compute the TOST p-values.
Term Estimate Std. Error z Pr(>|z|) S 5.0 % 95.0 %
average_magnitude 0.696 0.175 3.973 <0.001 13.8 0.408 0.984
eneg 0.158 0.204 0.779 0.436 1.2 -0.176 0.493
p (NonInf) p (NonSup) p (Equiv)
<0.001 0.6671 0.6671
<0.001 0.0117 0.0117
This doesn’t print super-nicely into this document, so let’s extract the important parts.
# hypothesis tests, extracting the important pieceshypotheses(c, equivalence =c(-m, m)) %>%select(term, estimate, conf.low, conf.high, p.value.equiv)
Term Estimate CI low CI high p (Equiv)
average_magnitude 0.696 0.408 0.984 0.6671
eneg 0.158 -0.176 0.493 0.0117
Checking that the 90% CIs fall within the bounds created by the smallest substantively-meaningful effect is equivalent to checking whether the TOST p-value (i.e., the p(Equiv) column) is less than 0.05, so our conclusions are (and must be) identical.
Other references
For more on effective arguments for no effect, see the following:
Lakens (2017) and Lakens, Scheel, and Isager (2018) offer an accessible introduction to equivalences tests for psychologists.
Fitzgerald (2025) offers and introduction to and argument for equivalence tests for economists.
Kane (2024) offers an excellent summary of design considerations when arguing for no effect.
McCaskey and Rainey (2015) (Ungated PDF) argue that researchers should make “claims if and only if those claims hold for the entire confidence interval.” This extends the logic of equivalence testing to a broader collection of possible hypotheses.
Final thoughts
{marginaleffects} is a great package (Arel-Bundock 2024). I think it’s the first package in which the syntax matches the way I think about computing quantities of interest. That said, this is just my first try at it. But I’m very impressed so far.
The {marginaleffects} bookModel to Meaning has a whole chapter on equivalence tests. My only caution is that there is a mismatch between 95% confidence intervals and equivalence tests. By default, {marginaleffects} reports a 95% CI, even when producing a p-value for an equivalence test. However, the 90% confidence interval correspondents to a size-5% equivalence test. So if you’re using {marginaleffects} to do equivalence tests, I recommend setting conf_level = 0.90.3
For a more recent example, Jares and Malhotra (2024) discusses negligible effects and hypothesis tests in a way that I find clear and compelling. It’s an excellent model to follow. See pp. 12-13. They “show that improved compensation outcomes had negligible impacts on Republican farmers’ midterm turnout and campaign contributions, even though such variation in benefits significantly affected farmers’ propensity to view the intervention as helpful.”
3 I would make a similar point about one-sided tests as well, but that’s less correct, because it should be a one-sided 95% CI.
References
Altman, D. G, and J M. Bland. 1995. “Statistics Notes: Absence of Evidence Is Not Evidence of Absence.”BMJ 311 (7003): 485–85. https://doi.org/10.1136/bmj.311.7003.485.
Clark, William Roberts, and Matt Golder. 2006. “Rehabilitating Duverger’s Theory.”Comparative Political Studies 39 (6): 679–708. https://doi.org/10.1177/0010414005278420.
Jares, Jake Alton, and Neil Malhotra. 2024. “Policy Impact and Voter Mobilization: Evidence from Farmers’ Trade War Experiences.”American Political Science Review 119 (2): 847–69. https://doi.org/10.1017/s0003055424000571.
Kane, John V. 2024. “More Than Meets the ITT: A Guide for Anticipating and Investigating Nonsignificant Results in Survey Experiments.”Journal of Experimental Political Science, February, 1–16. https://doi.org/10.1017/xps.2024.1.
Lakens, Daniël, Anne M. Scheel, and Peder M. Isager. 2018. “Equivalence Testing for Psychological Research: A Tutorial.”Advances in Methods and Practices in Psychological Science 1 (2): 259–69. https://doi.org/10.1177/2515245918770963.
McCaskey, Kelly, and Carlisle Rainey. 2015. “Substantive Importance and the Veil of Statistical Significance.”Statistics, Politics and Policy 6 (1-2). https://doi.org/10.1515/spp-2015-0001.
Nickerson, Raymond S. 2000. “Null Hypothesis Significance Testing: A Review of an Old and Continuing Controversy.”Psychological Methods 5 (2): 241–301. https://doi.org/10.1037/1082-989x.5.2.241.
Rainey, Carlisle. 2014. “Arguing for a Negligible Effect.”American Journal of Political Science 58 (4): 1083–91. https://doi.org/10.1111/ajps.12102.