Rows: 2,775
Columns: 15
$ release <chr> "V0.1 (Preprint)", "V0.1 (Preprint)", "V0.1 (Prepr…
$ release_date <date> 2023-12-18, 2023-12-18, 2023-12-18, 2023-12-18, 2…
$ data_source <chr> "IDEA", "IDEA", "IDEA", "IDEA", "IDEA", "IDEA", "I…
$ created_date <date> 2023-12-18, 2023-12-18, 2023-12-18, 2023-12-18, 2…
$ country_name <chr> "United States", "United States", "United States",…
$ ccode <dbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 20, 2…
$ stateabb <chr> "USA", "USA", "USA", "USA", "USA", "USA", "USA", "…
$ year <dbl> 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 19…
$ n_events <dbl> 135537, 140735, 151180, 177717, 194368, 195981, 20…
$ n_dissent_events <dbl> 118, 109, 124, 138, 127, 117, 123, 130, 147, 121, …
$ frac_dissent_events <dbl> 0.0008706110, 0.0007745053, 0.0008202143, 0.000776…
$ avg_pi <dbl> 0.0008690543, 0.0007750752, 0.0008211722, 0.000779…
$ avg_eta <dbl> -7.051493, -7.166315, -7.107983, -7.160229, -7.331…
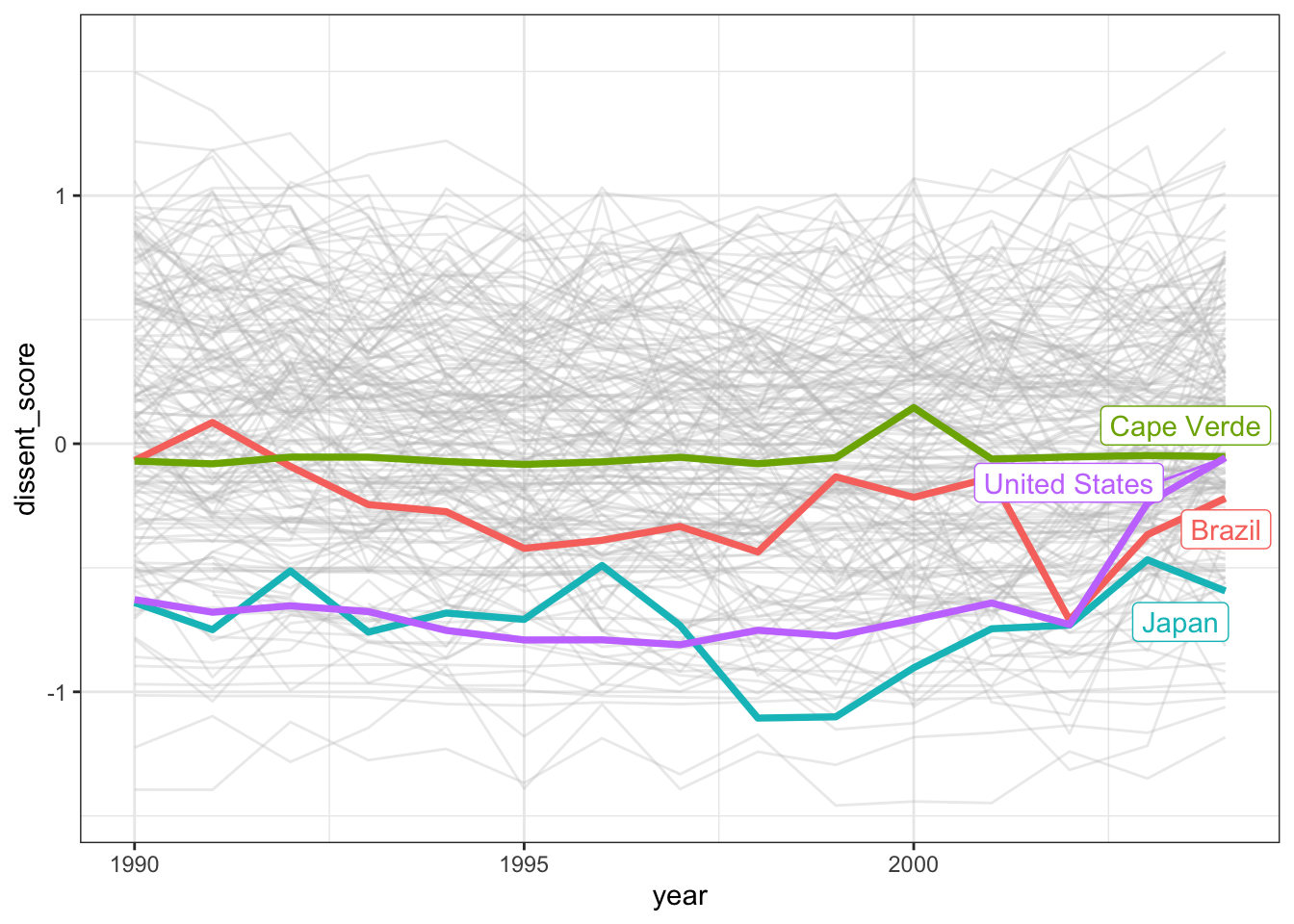
$ dissent_score <dbl> -0.62807636, -0.67911036, -0.65318394, -0.67640508…
$ se_dissent_score <dbl> 0.04107096, 0.04241524, 0.03997557, 0.03736980, 0.…