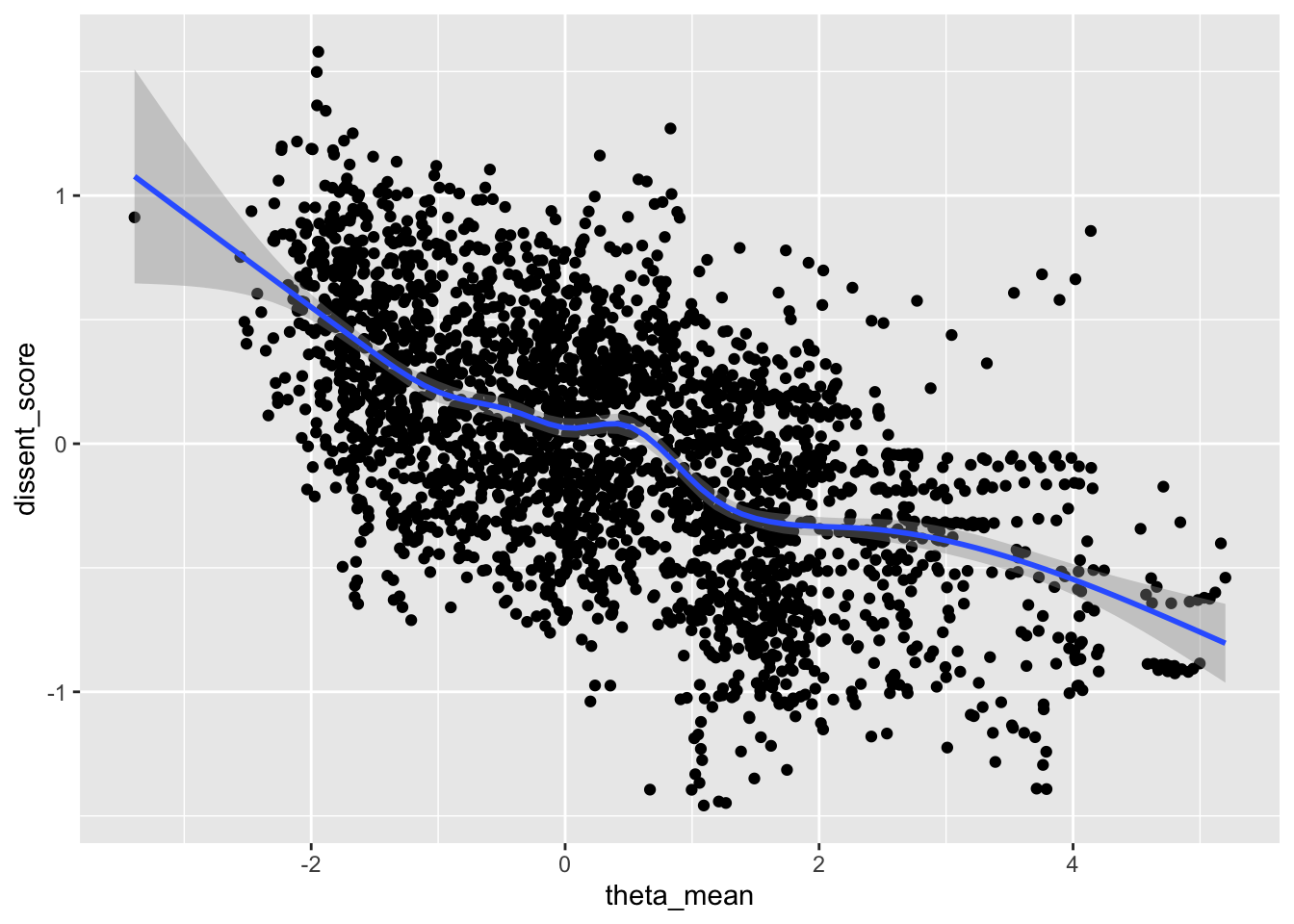
In this example, we download Fariss’ human rights score data set, download the dissent score data set, and plot the correlation between the two.
Orienting this correlation theoretically, we quote Davenport (2007) on “The Law of Coercive Responsiveness:”
By far the most long-standing and stable influence on state repression concerns political conflict. Dating back to, at least, Kautilya in India during the fourth century (particularly Book IV in the Arthashastra) or, more familiar to those in the West, Niccolo Machiavelli in Italy during the late 1400s and early 1500s or Thomas Hobbes in England during the late 1500s and early 1600s, it has been commonly thought that governing authorities should respond with repression to behavior that threatens the political system, government personnel, the economy, or the lives, beliefs, and livelihoods of those within their territorial jurisdiction. Quiescence is a major benefit to political authorities, supporting the extraction of taxes, the creation of wealth, and a major part of their legitimacy as a protector. Considering different time periods and countries, as well as a wide variety of measurements for both conflict and repression, every statistical investigation of the subject has found a positive influence. When challenges to the status quo take place, authorities generally employ some form of repressive action to counter or eliminate the behavioral threat; in short, there appears to be a “Law of Coercive Responsiveness.”
In brief, Davenport points out the correlation between the level of repression and the level of dissent. As an example, we show that correlation using our dissent score and Fariss’ human rights protection score.
# load packageslibrary(tidyverse)library(dataverse)# download latest version V4.01 of fariss' human rights protection scoreshrp_scores <-get_dataframe_by_name(filename ="HumanRightsProtectionScores_v4.01.tab",dataset ="10.7910/DVN/RQ85GK",server ="dataverse.harvard.edu") |># change variable names to match those used in the dissent scoresselect(year = YEAR, ccode = COW, theta_mean) |>glimpse()
# download latest version of dissent score data setdissent <-get_dataframe_by_name(filename ="dissent-scores.tab",dataset ="doi:10.7910/DVN/CL4CA8",server ="dataverse.harvard.edu", original =TRUE, .f = readr::read_csv) |>glimpse()